2021. 5. 11. 20:56ㆍData science/Python
*Data Engineering Process: Extract, Transform, Load
*Working with different file formats
1. Specify whether the file is a binary or ASCII file
2. How the information is organized (Comma-separated values, csv file format stores tabular data in plain text)
1) Reading CSV file
: spreadsheet file format, each cell is organized in rows and columns
: the type can be varied.
: Each record may contain one or more fields (separated by a comma)
: pandas.read_csv() function to read the csv file

#to make a columns attribute
df.columns =['First Name', 'Last Name', 'Location ', 'City','State','Area Code']
#To select single column
df["First Name"]
#To select multiple columns
df = df[['First Name', 'Last Name', 'Location ', 'City','State','Area Code']]
df
###To select rows using .iloc or .loc
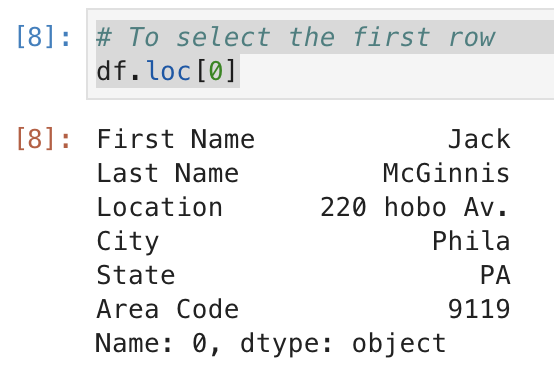
# To select the first row
df.loc[0]
# To select the 0th,1st and 2nd row of "First Name" column only
df.loc[[0,1,2], "First Name" ]
# To select the 0th,1st and 2nd row of "First Name" column only
df.iloc[[0,1,2], 0]*.loc()
: label based data selecting method which means that we have to pass the name of the row or column which we want to select
: .loc[index number] / df.loc[0] : return the index 0 rows of the dataFrame
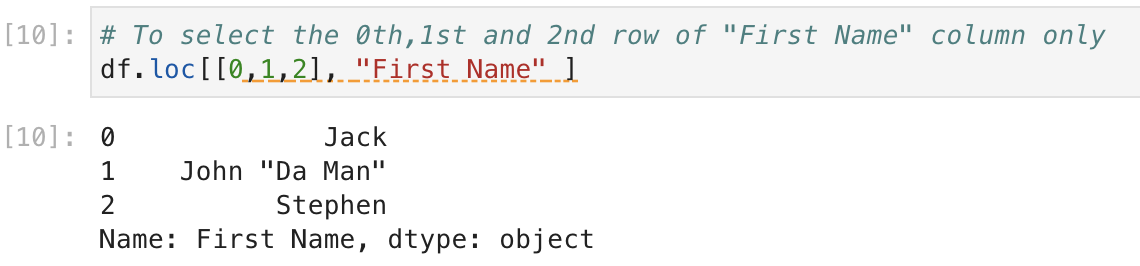
: .df.loc[[0,1,2], "First Name"]
-> return the row index 0,1,2 of column "First name"
*.iloc()

: indexed based selecting method which means that we have to pass integer index in the method to select a specific row/column
: df.iloc[[0,1,2], 0]
->return the row index 0,1,2 of column index 0
#Transfomr Function in Pandas
#import library
import pandas as pd
import numpy as np
#creating a dataFrame
df=pd.DataFrame(np.arrow)[[1,2,3], [4,5,6], [7,8,9]]), columns=['a','b','c'])
#applying the transform function(add 10 to each element)
df= df.tranform(func = lambda x:x+10)
#applyting the transform function(squaure root to each element)
result = df.transform(tunc=['sqrt'])
2. JSON file format (Javascript Object Notation): lightweight data-interchange format
: built on 2 structures
1) A collection of name/value pairs.(object, record, struct, dictionary, hash table, keyed list, associative array) 2) An ordered list of values (array, vector, list, sequence)
: language-independent data format
: done through quoted-string which contains the value in key-value mapping within {} (similar to python dictionary
Writing JSON to a File (serialization)
#Writing Json to a file "Serialization"
import json
person = {
'first_name' : 'Mark',
'last_name' : 'abc',
'age' : 27,
'address': {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021-3100"
}
}#serialization using dump() function : json.dump(dict, file_pointer)
#dictionary: name of dictionary which should be converted to JSON object
#file pointer: pointer of the file opened in write or append mode
with open('person.json', 'w') as f: # writing JSON object
json.dump(person, f)
print(person)
#result in 1 line
{'first_name': 'Mark', 'last_name': 'abc', 'age': 27, 'address': {'streetAddress': '21 2nd Street', 'city': 'New York', 'state': 'NY', 'postalCode': '10021-3100'}}
#serialization using dump() function : json.dump(dict, indent = 4)
#indent: defines the number of units for indentation to present the result readable
json_object - json.dumps(person, indent=4)
#writing to sample.json
with open("sample.json", "w") as outfile:
outfile.write(json_object)
print(json_object)
#result in a good shape(more readable)
{
"first_name": "Mark",
"last_name": "abc",
"age": 27,
"address": {
"streetAddress": "21 2nd Street",
"city": "New York",
"state": "NY",
"postalCode": "10021-3100"
}
}
Reading JSON to a file : Deserialization (convert special format returned by the serialization back into a usable object)
import json
#opening JSON file
with open('sample.json', 'r') as openfile:
#reading from json file
json_object = json.load(openfile)
print(json_object)
print(type(json_object))
#result
{'first_name': 'Mark', 'last_name': 'abc', 'age': 27, 'address': {'streetAddress': '21 2nd Street', 'city': 'New York', 'state': 'NY', 'postalCode': '10021-3100'}}
<class 'dict'>
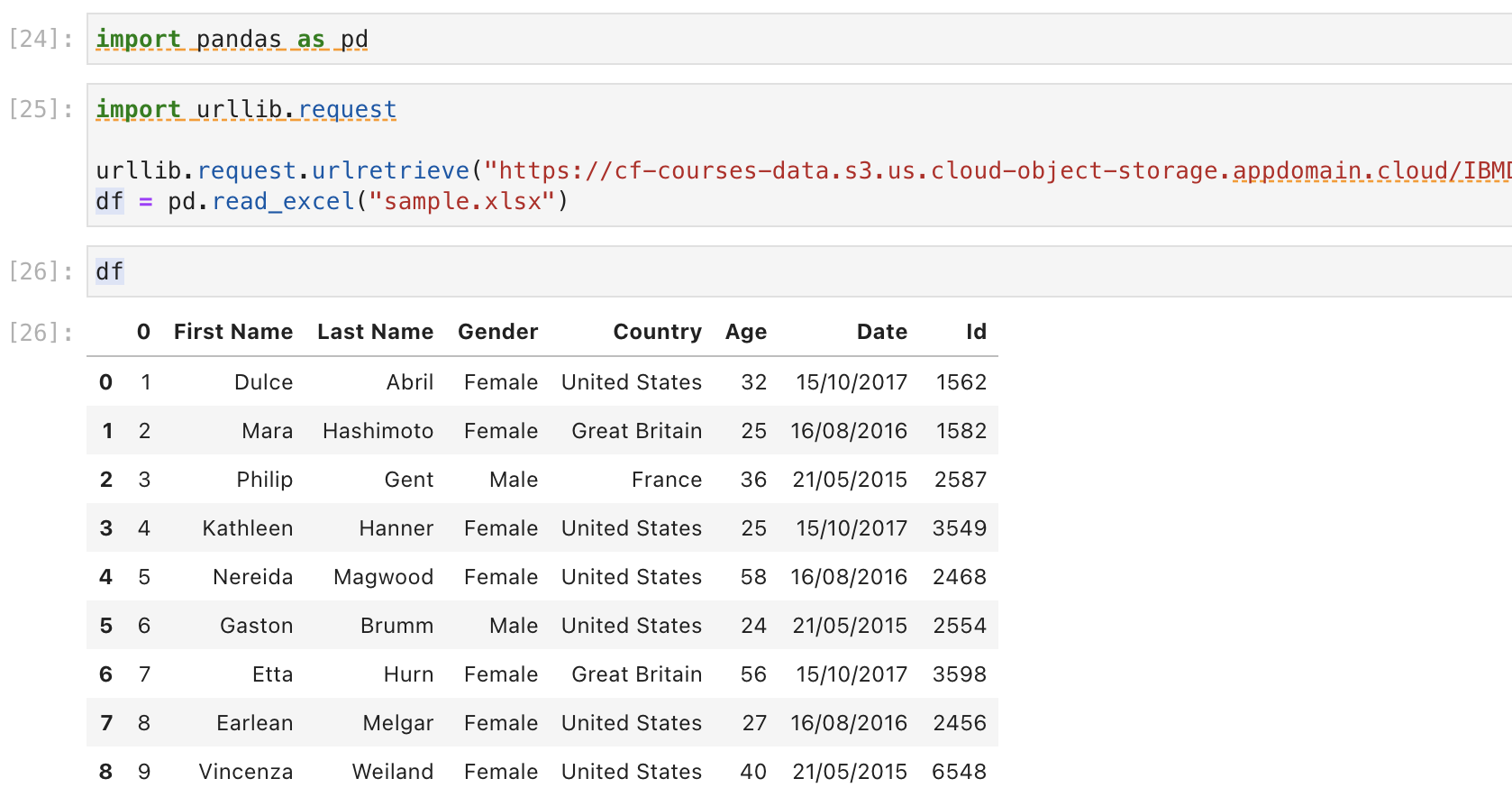
3.XLSX file format (Microsoft Excel Open XML file format) : under the cells and columns in a sheet
Reading the data from XLSX file
4.XML file format (Extensible Markup Langauge)
: human-readable and machine-readable file format
: it has certain rules for encoding data
*Writing with xml.etree.ElementTree: xml.etree.ElementTree module comes buit-in with Python
: parsing and creating XML documentation function
: represent XMl document as a tree
: move across the document using nodes which are elements and sub-elements of the XML file
import xml.etree.ElementTree as ET
#create the file structure
employee= ET.element('employee')
details = ET.SubElemenet(employee, 'details')
first = ET.SubElement (details, 'firstname')
second = ET.SubElement(details, 'lastname')
third = ET.SubElement(details, 'age')
first.text = 'Shiv'
second.text = 'Mishra'
third.text = '23'
#create a new XML file with the results
mydata1 = ET.ElementTree(employee)
#myfile = open("items2.xml","wb")
#myfile.write(mydata)
with open("new_sample.xml", "wb") as files:
mydata1.write(files)*Reading with xml.etree.ElementTree
import pandas as pd
import xml.etree.ElementTree as etree
#save the notepad on my computer
!wget http://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0101EN-SkillsNetwork/labs/Module%205/data/Sample-employee-XML-file.xml
#parse an XML file and create a list of columns for DataFrame,
#then extract useful information from XML file and add to a pandas DataFrame
tree = etree.parse("Sample-employee-XML-file.xml")
root = tree.getroot()
columns =["firstname", "lastname", "title","division","building","room"]
dataframe = pd.DataFrame(columns=columns)
for node in root:
firstname = node.find("firstname").text
lastname =node.find("lastname").text
title = node.find("title").text
division = node.find("division").text
building = node.find("building").text
room = node.find("room").text
dataframe - dataframe.append(pd.Series([firstname, lastname, title, division, building, room], index = columns), ignore_index = True)
dataframe 
*Save DATA : dataframe.to_csv() - Pandas enables us to save the dataset to csv file
datatframe.to_csv("employee.csv", index=False) #index to extract :True, no index : False
Also other data formats can be read and saved.