2023. 1. 16. 08:33ㆍData science/Database
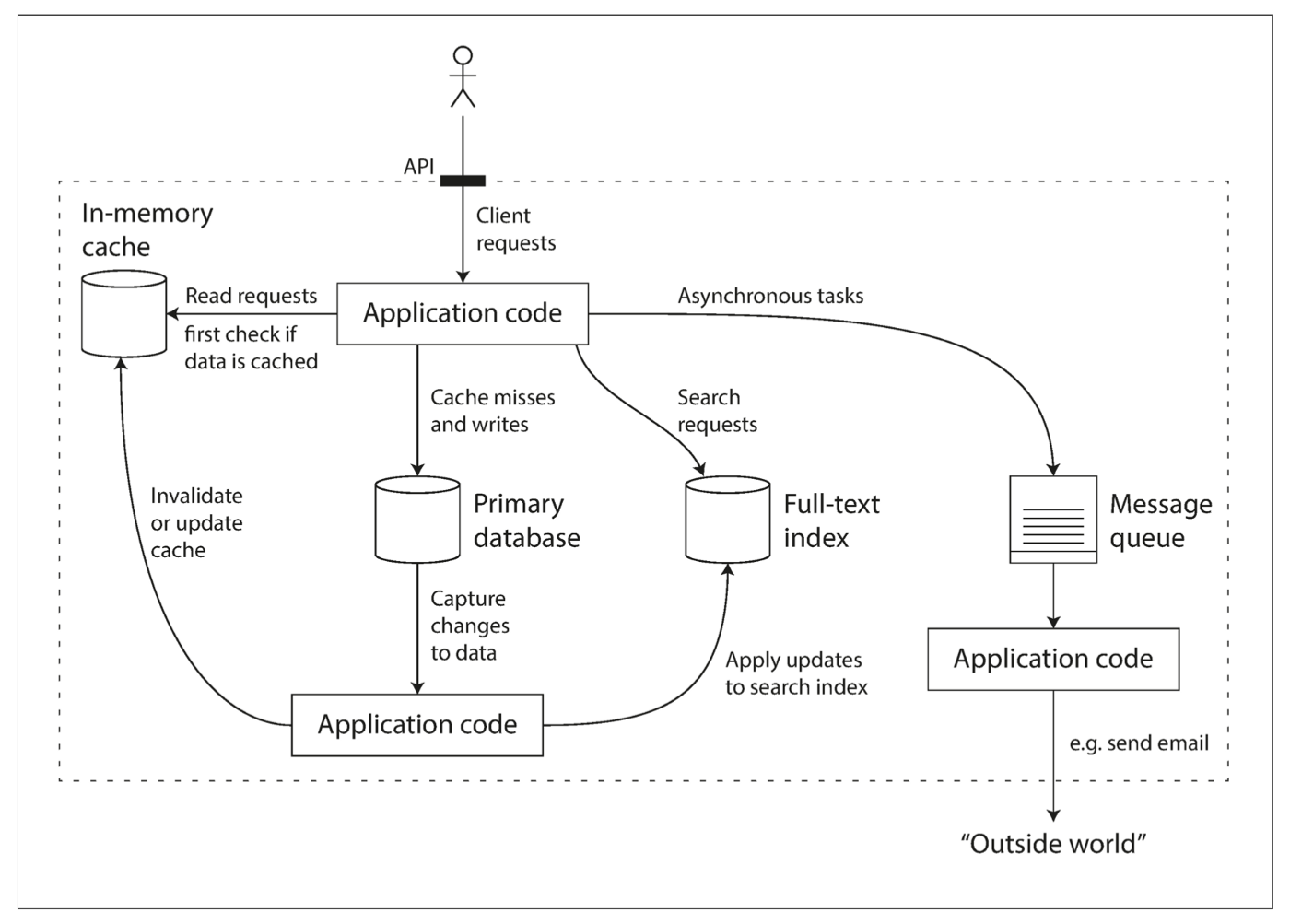
Data Systems
: combines different data storage technologies
: caches, indexes and data in sync with application code
: API(application programming interface) to hide architectural complexity
: There are three ways to deal with requests in this figure, 1. In-memory cache 2. Primary database 3. Full-text index
- Before checking DB, check the cache to see if the data is cached.
- If there is no cache, go to DB.
- If we get search requests, check the full-text index. But this makes to read a lot of documents which takes a long time
- When the operations don't need to process immediately (Asynchronous task - i.e. email), approach differently.
Q1. How do you ensure the data remains correct and complete, even when things go wrong internally?
Q2. How do you provide consistently good performance to clients, even when parts of your system are degraded?
Q3. How do you scale to handle an increase in load?
Reliability, Scalability and Maintainability
| Reliability | Scalability | Maintainability |
| * perform as the user expected * tolerate the user's mistake * good enough performance for the required use case by the user * prevent any unauthorized access or abuse |
* Ability to cope with increased load * described using load parameters * or using fan-out * using throughput(batch-processing) * response time(online system) |
* Operability: running smoothly * Simplicity: easy for new engineers * Evolvability: easy to make changes in the future, adapting it for unanticipated use cases as requirements changes |
Another question?! Case study of Twitter
Approach 1. follows table, tweets table, and users table store data individually and link them to get the outcome
Approach 2. Make a time-lined tweets list per user in DB and print it out immediately. (Fan-out: Deliver tweet to each follower, up to 31M followers per user)
-> Which approach is better?????
Scaling Out
- Scaling up: Vertical scaling, upgrade to more powerful machines (Not used these days)
- Scaling out: Horizontal scaling, Distributing the load across multiple smaller machines(adding more instances)
- Centralized database: Using one centralized DB in one area, the local office gets data from there.
- Distributed database: Using multiple local DB (user closer DB used)
Replication
Replication means keeping a copy of the same data on multiple machines that are connected via a network
- keep data geographically close to users
- increase availability(even though other parts failed)
- increase read throughput(scale out the number of machines)
: Single-leader, Multi-Leader or Leaderless replication can be applied
- One of the replicas is designated as the leader(primary or master)
- The other replicas are known as followers (secondary, hot standby, slaves, read replicas)
- Read Query can be done by either leader or followers
Synchronous: data is consistent, but if the follower doesn't respond -> the writing doesn't work.
Asynchronous: Eventual consistency, but it will always work
#Handling Node Outage
Follower Failure: Catchup Recovery
Leader Failure: Failover (1. Determine the leader fails, 2. Choosing a new leader, 3. Reconfigure the system to use a new leader) - When elects the leader, there is a vote. Details can be found in MongoDB documents.
#Problem with Replication Lag: The figures show the problem, and the solution is given in the statement
1. Reading stale data solution: read your own write - after write, the replica is not up-to-dated
- when reading something the user may have modified, read it from the leader.

2. Backward Time travel solution: Monotonic read - the update is yet to reach a certain replica.
- Each user always makes their read from the same replica


3. Observer Dejavu solution: Consistent prefix read - For the Observer, the message from Mrs.cake shows up first.
- writes in that same order (read always see a consistent prefix)
- any writes related to each other should write in the same partition

Multi-Leader Replication
: Performance improvement, Tolerance of DC(Data Centre) outage and network Problem
: Client with offline operations(Calendar), Collaborative editing(Google docs)
: There can be a conflict in writing data.
#Solution of Write Conflicts (Multi-Leader Replication)
- making the conflict detection synchronous
- all writes for particular records go through the same leader
- give each write a unique ID, and pick the write with the highest one is the winner(the latest one)
- recording the conflict in an explicit data structure that preserves all info
- to be automatically resolved by the application or the user at a later time
https://towardsdatascience.com/database-replication-explained-10ff929bdf8a
Excellent blog summarised the solution in detail.
Leaderless Replication
: Quorom reading, writing - wait until at least N/2 + 1 nodes returns ACK (W+R>N)
: Read repair - stale data
: Anti-entropy process - if they are not read, some values can be missed
: High consistency


Partitioning(Sharding)
In MongoDB, the term Sharding is used for Partitioning.
: It is usually combined with replication, and they are stored on multiple nodes for fault tolerance(Allocation)
Partition by key range: Assign a continuous range of keys to each partition.
Partition by Hash of Key: Risk of skew and hot spots, a hash can be sued instead of the key range. But, the capability of efficient range query will be lost.
Rebalancing
- The query throughput increases - more CPUs required
- The data size increases - more disk and RAM required
- A machine field - another machine to take over failed one's responsibility
Therefore, rebalancing can be used for data and request fairness and no downtime.
The strategy: Fixed number of partitions.
Figure below, first it was 5 partitions in 4 nodes -> relocate the partitions and make them as 4 partitions in 5 nodes

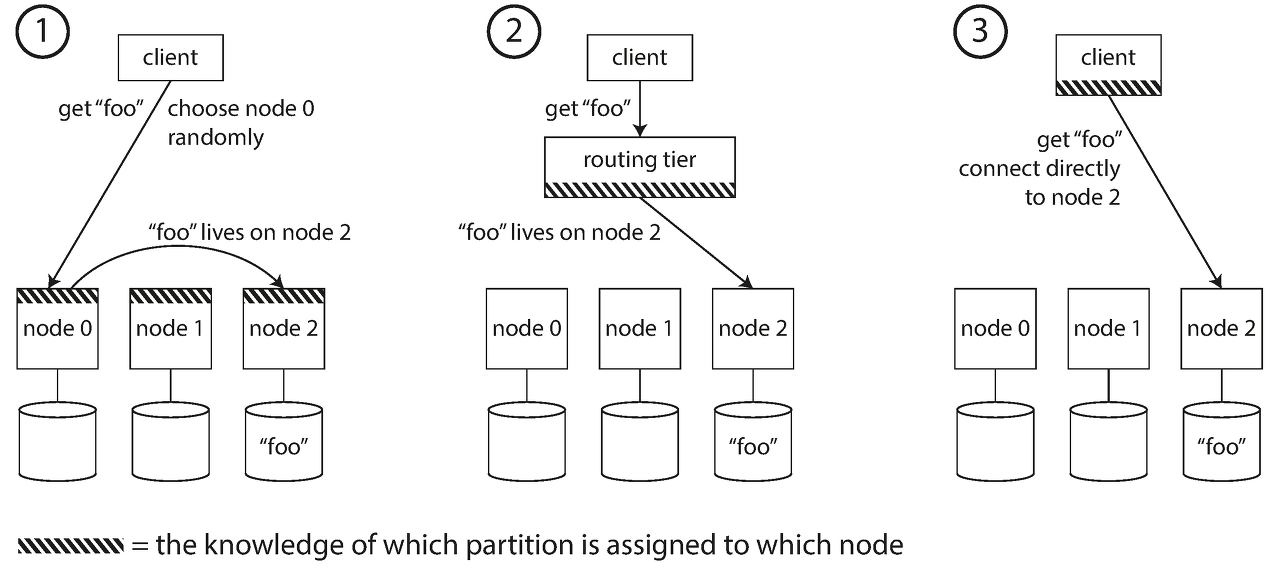
Request Routing
- Allow clients to contact any node
- Send all requests from clients to the routing tier first
- Require that clients be aware of the partitioning and the assignment of partitions to nodes
'Data science > Database' 카테고리의 다른 글
| Understanding Database 11 - Database Programming Techniques (0) | 2023.01.16 |
|---|---|
| Understanding Database 10 - Data modelling with MongoDB (0) | 2023.01.16 |
| Understanding Database 8 - NoSQL + Python Basic (0) | 2023.01.16 |
| Understanding database 7 - NoSQL (0) | 2023.01.16 |
| Understanding database 6 - Normalization (0) | 2023.01.15 |