2023. 1. 16. 09:06ㆍData science/Database
Modelling for RDBMS
1. Define schema
2. develop the application and DB queries
-> One correct solution, no revision/Data duplicates /Usage makes schema demoralised(Performace dropping)
Modelling for MongoDB
1. Develop and define the data model
2. re-define data model
3. Improve the application
4. improve the data model
5. repeat cycle 3 and 4
-> Multiple design options/design for usage patterns/Design evolution easy and intuitive (possible without downtime)
※ Things to consider: Data model is defined at the application level/Design is an integral part of each phase of the application lifetime/affected by changes in the app's data need and read and write data usage.
Data Modelling Method
- Evaluate Application workload
- Map out entities and their relationships
- Finalize data model for each collection
| Evaluate Application workload | Map out entities and their relationships | Finalize data model for each collection | Outcome |
| - by a business domain expert - consider the current, predicted and future scenarios - consider production logs and matrix - consider the data size - consider the operations lists ranked by importance(speed, accuracy, etc) |
- Link or Embedded? (by Collection Relationship Diagram- CRD) |
- considering data size - considering database queries and indexes - considering current operations and assumptions - identify and apply relevant design patterns |
- Data size - Collection with fields and shapes - queries and index - assumptions and future/growth projections |
| ** Operations? ** Cardinality? |
** How often the embedded info be accessed? ** embedded info changes often? ** queries used embedded data? ** embedded data to be sued together? |
** Schema versioning ** Bucket Pattern ** Computed pattern |
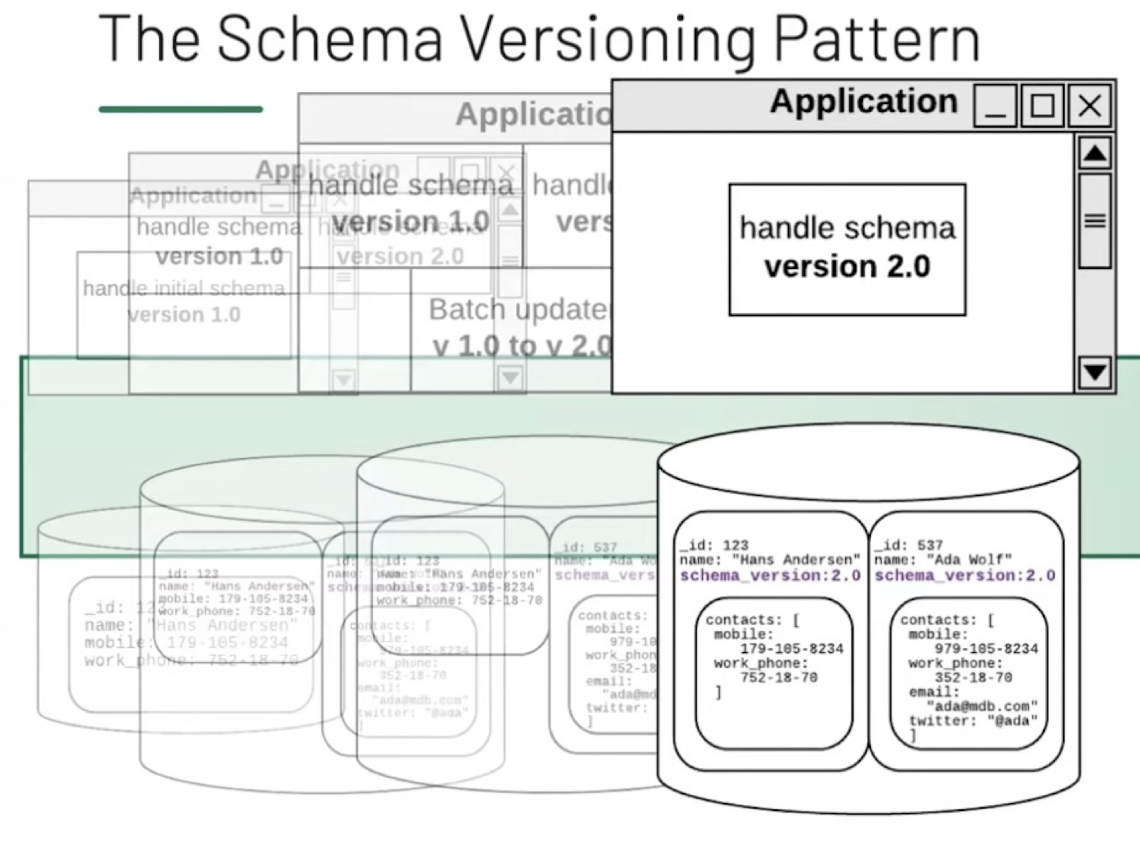
Design Patterns: Schema versioning
Schema can be revised, and then instead of updating the entire fields, you can write Schema_version: 2.0 with newly added fields.
Design Patterns: Bucket pattern
- reduce index sizes by a large magnitude, increase the speed of retrieval of related data
- From the below figure, if the "valcount" reaches 200, a new document is created automatically and starts storing in the new document.

Design Pattern: Computed Pattern
- instead of using the computed result in the document, keep the total count and qty(summary records)
- reads are more common than writing, compute on write is less work than compute on read, kinds of caching pattern

-> MongoDB Youtube provide an excellent explanation for this part.
'Data science > Database' 카테고리의 다른 글
| Understanding Database - SQL 기초 총정리 (2) | 2023.01.23 |
|---|---|
| Understanding Database 11 - Database Programming Techniques (0) | 2023.01.16 |
| Understanding Database 9 - Distributed Database Systems(DDB) (0) | 2023.01.16 |
| Understanding Database 8 - NoSQL + Python Basic (0) | 2023.01.16 |
| Understanding database 7 - NoSQL (0) | 2023.01.16 |